Trong bài viết này chúng ta sẽ tìm hiểu về cách sử dụng Redis cache để tăng hiệu suất cho backend, bao gồm các khái niệm cơ bản, các trường hợp ứng dụng cụ thể, chiến lược quản lý cache, và một số mẹo tối ưu.
1. Redis là gì?
Redis (Remote Dictionary Server) là một cơ sở dữ liệu key-value lưu trữ dữ liệu trong bộ nhớ (in-memory), nổi tiếng nhờ tốc độ truy xuất cực nhanh. Redis hỗ trợ nhiều kiểu dữ liệu như:
- String: Chuỗi văn bản (thường là dạng key-value đơn giản nhất).
- List: Danh sách các phần tử theo thứ tự, hỗ trợ push, pop từ đầu và cuối danh sách.
- Set: Tập hợp không có thứ tự, mỗi phần tử là duy nhất, hỗ trợ các phép toán tập hợp như union và intersection.
- Hash: Tương tự một dictionary, dùng để lưu trữ các key-value trong một key chính.
- Sorted Set: Tập hợp có thứ tự, trong đó mỗi phần tử có một “điểm số” dùng để sắp xếp.
Redis thường được dùng để cache dữ liệu do tốc độ truy cập bộ nhớ nhanh hơn rất nhiều so với các hệ thống lưu trữ dữ liệu truyền thống trên đĩa như MySQL hoặc PostgreSQL.
2. Tại sao Redis cache tăng hiệu suất cho backend?
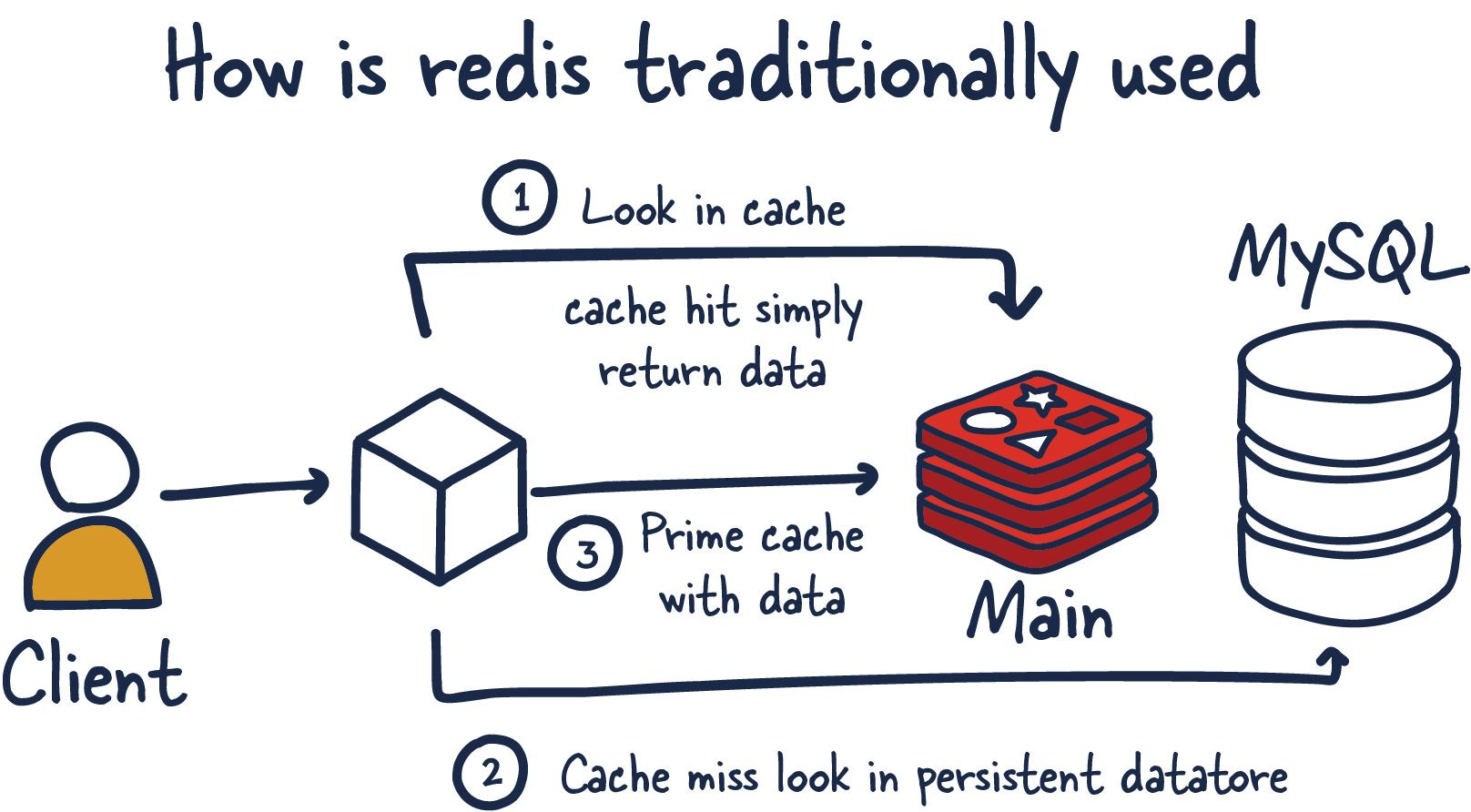
Redis cache tăng hiệu suất cho backend
Redis cache giúp tăng tốc ứng dụng nhờ vào những lợi ích sau:
- Hiệu suất cao: Do tất cả dữ liệu được lưu trữ và truy xuất trực tiếp từ RAM, Redis cho tốc độ truy cập cực nhanh với độ trễ thấp. Redis có khả năng xử lý hàng triệu yêu cầu mỗi giây, rất phù hợp cho các ứng dụng cần đáp ứng lượng lớn người dùng.
- Giảm tải cho cơ sở dữ liệu chính: Khi dữ liệu đã được lưu trong cache Redis, số lượng truy vấn đến cơ sở dữ liệu gốc giảm đáng kể. Điều này giảm tải và tăng tuổi thọ cho cơ sở dữ liệu chính, cũng như cải thiện tốc độ xử lý của ứng dụng.
- Hỗ trợ TTL (Time-To-Live): Redis cho phép đặt thời gian sống cho mỗi key (TTL), sau đó dữ liệu sẽ tự động xóa khỏi cache, giúp giải phóng bộ nhớ và giữ cho cache được cập nhật.
- Khả năng mở rộng tốt: Redis hỗ trợ clustering và replication, giúp chia tải và phân phối dữ liệu giữa nhiều node. Điều này giúp Redis có khả năng mở rộng và chịu tải cao.
3. Redis cache trong các trường hợp sử dụng thực tế
a. Caching dữ liệu từ cơ sở dữ liệu
Một trường hợp phổ biến là caching các kết quả truy vấn cơ sở dữ liệu. Thay vì phải truy vấn trực tiếp từ cơ sở dữ liệu nhiều lần, bạn có thể lưu kết quả vào Redis. Khi cần dữ liệu, ứng dụng kiểm tra cache trước, nếu có sẽ trả về ngay lập tức, giảm đáng kể thời gian phản hồi.
Ví dụ: Caching thông tin người dùng
Khi ứng dụng cần lấy thông tin người dùng, đầu tiên nó sẽ kiểm tra Redis xem dữ liệu đã có trong cache chưa. Nếu có (cache hit), trả về dữ liệu ngay lập tức; nếu không (cache miss), nó truy vấn từ cơ sở dữ liệu và lưu lại trong cache.
const getUserData = async (userId) => {
const cacheKey = `user:${userId}`;
const cachedUser = await client.get(cacheKey);
if (cachedUser) {
return JSON.parse(cachedUser); // Trả về dữ liệu đã cache
}
// Nếu cache miss, truy vấn từ cơ sở dữ liệu
const userData = await database.getUserById(userId);
// Lưu dữ liệu vào cache và thiết lập TTL là 1 giờ
await client.set(cacheKey, JSON.stringify(userData), 'EX', 3600);
return userData;
};
b. Caching kết quả của các API
Redis có thể cache các phản hồi của API, đặc biệt là các API phức tạp hoặc xử lý nhiều dữ liệu từ cơ sở dữ liệu. Điều này giảm tải cho hệ thống và tăng tốc độ phản hồi.
Ví dụ: Caching kết quả từ một API thời tiết
Thay vì truy vấn thời tiết trực tiếp từ một API thời tiết mỗi khi có yêu cầu, bạn có thể cache kết quả và chỉ làm mới dữ liệu sau một thời gian nhất định.
const getWeather = async (city) => {
const cacheKey = `weather:${city}`;
const cachedWeather = await client.get(cacheKey);
if (cachedWeather) {
return JSON.parse(cachedWeather);
}
// Lấy dữ liệu từ API thời tiết nếu không có trong cache
const weatherData = await weatherApi.getWeatherByCity(city);
// Cache lại với TTL là 15 phút
await client.set(cacheKey, JSON.stringify(weatherData), 'EX', 900);
return weatherData;
};
c. Caching session (phiên) người dùng
Redis là một lựa chọn phổ biến để lưu trữ session của người dùng do tốc độ truy xuất nhanh và khả năng xử lý dữ liệu không đồng bộ. Khi session được lưu trong Redis, việc truy xuất session của người dùng trở nên nhanh chóng và dễ dàng hơn, giúp giảm tải cho các cơ sở dữ liệu truyền thống.
d. Caching các tính toán phức tạp hoặc tài liệu (document)
Redis có thể lưu trữ kết quả của các tính toán hoặc xử lý phức tạp, giúp tránh phải thực hiện lại những tác vụ nặng này mỗi lần có yêu cầu.
4. Chiến lược quản lý cache trong Redis
Để tối ưu hóa việc sử dụng Redis cache, bạn cần áp dụng một số chiến lược quản lý cache hiệu quả:
a. Cache-aside (Lazy Loading)
Cache-aside (Lazy Loading)
Đây là chiến lược phổ biến nhất: ứng dụng sẽ kiểm tra cache trước khi truy vấn cơ sở dữ liệu. Nếu có cache hit, dữ liệu trả về ngay lập tức; nếu cache miss, truy vấn từ cơ sở dữ liệu và lưu kết quả vào cache.
- Ưu điểm: Đơn giản, giảm tải hiệu quả cho cơ sở dữ liệu.
- Nhược điểm: Khi cache miss, vẫn cần truy vấn cơ sở dữ liệu, có thể làm giảm hiệu suất.
b. Write-through
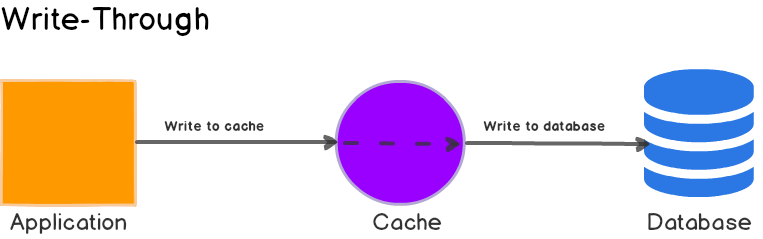
Write-through
Trong chiến lược này, bất cứ khi nào dữ liệu được ghi vào cơ sở dữ liệu, nó cũng sẽ được ghi vào cache ngay lập tức. Điều này đảm bảo dữ liệu trong cache luôn đồng bộ với cơ sở dữ liệu.
- Ưu điểm: Đảm bảo tính đồng bộ dữ liệu giữa cache và cơ sở dữ liệu.
- Nhược điểm: Làm chậm tốc độ ghi dữ liệu vì cần ghi vào cả cache và cơ sở dữ liệu.
c. Write-behind (Write-back)
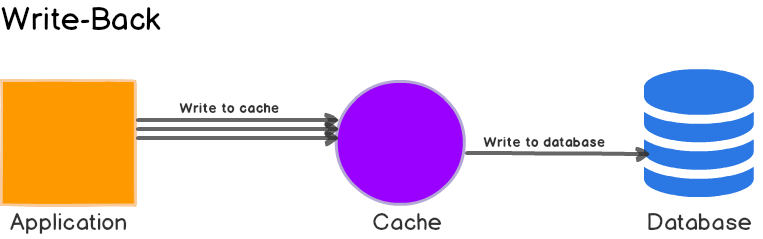
Write-behind (Write-back)
Chiến lược này ghi dữ liệu vào cache trước và sau đó cập nhật cơ sở dữ liệu trong nền (asynchronously). Cách này tăng tốc độ ghi nhưng có thể gây ra các vấn đề về tính đồng bộ dữ liệu.
- Ưu điểm: Tăng tốc độ ghi dữ liệu.
- Nhược điểm: Có thể dẫn đến vấn đề mất đồng bộ dữ liệu giữa cache và cơ sở dữ liệu.
d. TTL và Eviction Policy
Redis hỗ trợ TTL để tự động xóa dữ liệu sau một thời gian xác định. Ngoài ra, khi bộ nhớ đạt đến giới hạn, Redis sẽ thực hiện “eviction” (loại bỏ key) dựa trên các chính sách:
- LRU (Least Recently Used): Xóa các key ít được truy cập nhất.
- LFU (Least Frequently Used): Xóa các key ít được truy cập thường xuyên.
- TTL-based: Xóa các key sắp hết hạn trước.
5. Một số lưu ý khi sử dụng Redis cache
a. Xác định dữ liệu nên cache
Cache nên được sử dụng cho dữ liệu:
- Truy xuất thường xuyên.
- Có độ phức tạp cao, tốn nhiều thời gian xử lý.
- Ít thay đổi trong khoảng thời gian ngắn.
Các dữ liệu ít quan trọng hoặc thay đổi liên tục không nên cache để tránh việc tốn bộ nhớ và gây nhầm lẫn do dữ liệu cũ.
b. Quản lý bộ nhớ cẩn thận
Redis lưu trữ dữ liệu trên bộ nhớ RAM, vì vậy cần kiểm soát cẩn thận các key đã lưu và TTL để tránh quá tải bộ nhớ. Bạn cũng có thể sử dụng Redis Cluster để phân tán dữ liệu và tăng dung lượng bộ nhớ.
c. Cài đặt cơ chế fallback (dự phòng)
Trong trường hợp Redis gặp sự cố, ứng dụng cần có cơ chế fallback để truy vấn cơ sở dữ liệu gốc. Điều này đảm bảo hệ thống vẫn hoạt động ngay cả khi không có cache.
6. Kết luận
Redis cache là một giải pháp mạnh mẽ giúp tăng hiệu suất backend bằng cách giảm tải cho cơ sở dữ liệu, tăng tốc độ truy xuất dữ liệu và cải thiện trải nghiệm người dùng. Việc áp dụng các chiến lược quản lý cache và tối ưu hóa Redis sẽ giúp bạn đạt được hiệu suất tối ưu và mở rộng khả năng xử lý của hệ thống.